Redis 各种数据结构的内部原理
基本结构 redisObject
Redis 的 key 是顶层模型,它的 value 是扁平化的。Redis 中,所有的 value 都是一个 Object,它的结构如下:
typedef struct redisObject {
unsigned [type] 4;
unsigned [encoding] 4;
unsigned [lru] REDIS_LRU_BITS;
int refcount;
void *ptr;
} robj;
简单介绍一下这几个字段:
- type:数据类型,就是我们熟悉的 string、hash、list 等。
- encoding:内部编码,其实就是本文要介绍的数据结构。指的是当前这个 value 底层是用的什么数据结构。因为同一个数据类型底层也有多种数据结构的实现,所以这里需要指定数据结构。
- REDIS_LRU_BITS:当前对象可以保留的时长。
- refcount:对象引用计数,用于GC。
- ptr:指针,指向以 encoding 的方式实现这个对象的实际地址。

String 类型
String 类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg 图片或者序列化的对象。
字符串可以存储以下3种类型的值。
- 字节串(byte string,包括二进制数据)
- 整数。
- 浮点数。
用户可以通过给定一个任意的数值,对存储着整数或者浮点数的字符串执行自增(increment)或者自减(decrement)操作,在有需要的时候,Redis 还会将整数转换成浮点数。
在 Redis 内部,string 类型有两种底层储存结构。Redis 会根据存储的数据及用户的操作指令自动选择合适的结构:
- int:存放整数类型;
- SDS:存放浮点、字符串、字节类型;
注:SDS: 简单动态字符串 simple dynamic string
整数的取值范围和系统的长整数(long integer)的取值范围相同(在 32 位系统上,整数就是 32 位有符号整数,在 64 位系统上,整数就是 64 位有符号整数),而浮点数的取值范围和精度则与 IEEE 754 标准的双精度浮点数(double)相同。
Redis 明确地区分字节串、整数和浮点数的做法是一种优势,比起只能够存储字节串的做法,Redis 的做法在数据表现方面具有更大的灵活性。
SDS(动态字符串)原理
Redis 默认并未直接使用 C 字符串(C字符串仅仅作为字符串字面量,用在一些无需对字符串进行修改的地方,如打印日志)。而是以 Struct 的形式构造了一个 SDS 的抽象类型。当 Redis 需要一个可以被修改的字符串时,就会使用 SDS 来表示。
在 Redis 数据库里,包含字符串值的键值对都是由 SDS 实现的(Redis 中所有的键都是由字符串对象实现的即底层是由 SDS 实现,Redis 中所有的值对象中包含的字符串对象底层也是由 SDS 实现)。
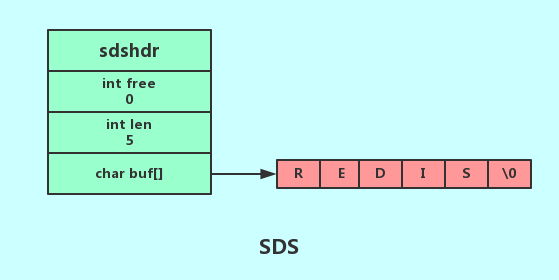
SDS 的内部数据结构:
typedef struct sdshdr {
// int 记录buf数组中未使用字节的数量 如上图free为0代表未使用字节的数量为0****
// 即:buf中已经占用的字符长度
unsigned int len;
//int 记录buf数组中已使用字节的数量即sds的长度 如上图len为5代表未使用字节的数量为5
// 即:buf中剩余可用的字符长度
unsigned int free;
// 字节数组用于保存字符串 sds遵循了c字符串以空字符结尾的惯例目的是为了重用c字符串函数库里的函数
char buf[];
}
为什么要使用 SDS?😮
可见,其底层是一个 char 数组。buf 最大容量为 512M,里面可以放字符串、浮点数和字节。所以你甚至可以放一张序列化后的图片。它为什么没有直接使用数组,而是包装成了这样的数据结构呢?
关于为什么 Redis 要使用 SDS 而不是 C 字符串,我们可以从以下几个方面来分析。
buf 可能需要扩容
buf 会有动态扩容和缩容的需求。如果直接使用数组,那每次对字符串的修改都会导致重新分配内存,效率很低。
下面来看下 SDS 空间预分配策略:
如果修改后 len 长度将小于 1M,这时分配给 free 的大小和 len 一样,例如修改过后为 10字节,那么给 free 也是 10字节,buf 实际长度变成了 10 + 10 + 1 = 21byte
如果修改后 len 长度将大于等于 1M,这时分配给 free 的长度为 1M,例如修改过后为 30M,那么给 free 是 1M,buf 实际长度变成了 30M + 1M + 1byte
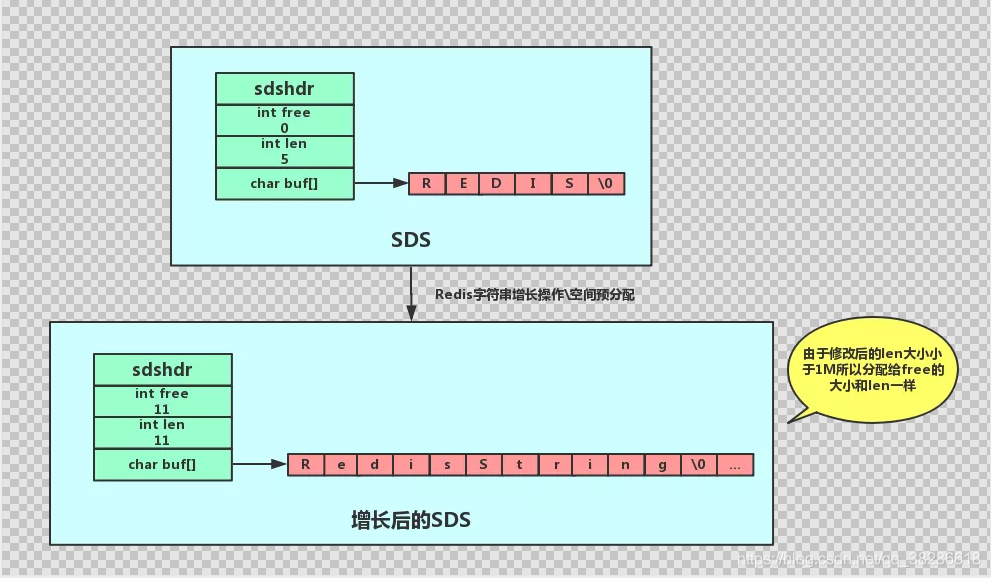
惰性空间释放
惰性空间释放指的是当字符串缩短时,并没有真正的缩容,而是移动 free 的指针。这样将来字符串长度增加时,就不用重新分配内存了。
Redis 通过空间预分配和惰性空间释放策略在字符串操作中一定程度上减少了内存重分配的次数。但这种策略同样会造成一定的内存浪费,因此 Redis SDS API 提供相应的 API 让我们在有需要的时候真正的释放 SDS 的未使用空间。
缓冲区溢出
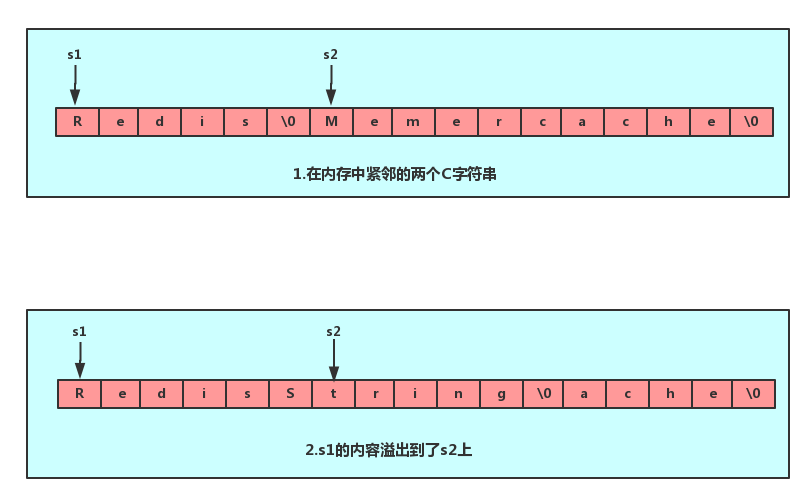
C 字符串,如果程序员在字符串修改的时候如果忘记给字符串重新分配足够的空间,那么就会发生内存溢出
如上图所示,如果没有给 s1 分配足够的内存空间,s1 的数据就会溢出到 s2 的空间,导致 s2 的内容被修改。而 Redis 提供的 SDS 其内置的空间分配策略则可以完全杜绝这种事情的发生。当 API 需要对 SDS 进行修改时,API 会首先会检查 SDS 的空间是否满足条件,如果不满足,API 会自动对它动态扩展,然后再进行修改。(如果每次都修改都分配内存效率很低)
二进制安全
C 字符串中的字符必须符合某种编码(比如 ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存像图片、音频、视频、压缩文件这样的二进制数据。
如果有一种使用空字符来分割多个单词的特殊数据格式,就不能用 C字符串来表示,如 "Redis\0String",C 字符串的函数会把 '\0' 当做结束符来处理,而忽略到后面的 "String"。而 SDS 的 buf 字节数组不是在保存字符,而是一系列二进制数组,SDS API 都会以二进制的方式来处理 buf 数组里的数据,使用 len 属性的值而不是空字符来判断字符串是否结束。
时间复杂度
我们来看几个 Redis 常见操作的时间复杂度。
- 获取SDS长度: 由于SDS中提供了len属性,因此我们可以直接获取时间复杂度为 ,C字符串为 。
- 获取 SDS 未使用空间长度: 时间复杂度为 ,原因同1。
- 清除 SDS 保存的内容:由于惰性空间分配策略,复杂度为 。
- 创建一个长度为 N 的字符串:时间复杂度为 。
- 拼接一个长度为 N 的 C字符串:时间复杂度为 。
- 拼接一个长度为 N 的 SDS 字符串:时间复杂度为 。
Redis 在获取字符串长度上的时间复杂度为常数级 。
总结:为什么要使用 SDS
通过以上分析,我们可以得到,SDS这种数据结构相对于C字符串有以下优点:
- 杜绝缓冲区溢出
- 减少字符串操作中的内存重分配次数
- 二进制安全
- 由于 SDS 遵循以空字符结尾的惯例,因此兼容部门C字符串函数
Redis 定位于一个高性能的内存数据库,其面向的就是大数据量,大并发,频繁读写,高响应速度的业务。因此在保证安全稳定的情况下,性能的提升非常重要。
而 SDS 这种数据结构屏蔽了C字符串的一些缺点,可以提供安全高性能的字符串操作。
List 类型
list 底层有两种数据结构:链表 linkedlist 和压缩列表 ziplist。当 list 元素个数少且元素内容长度不大时,使用 ziplist 实现,否则使用 linkedlist。
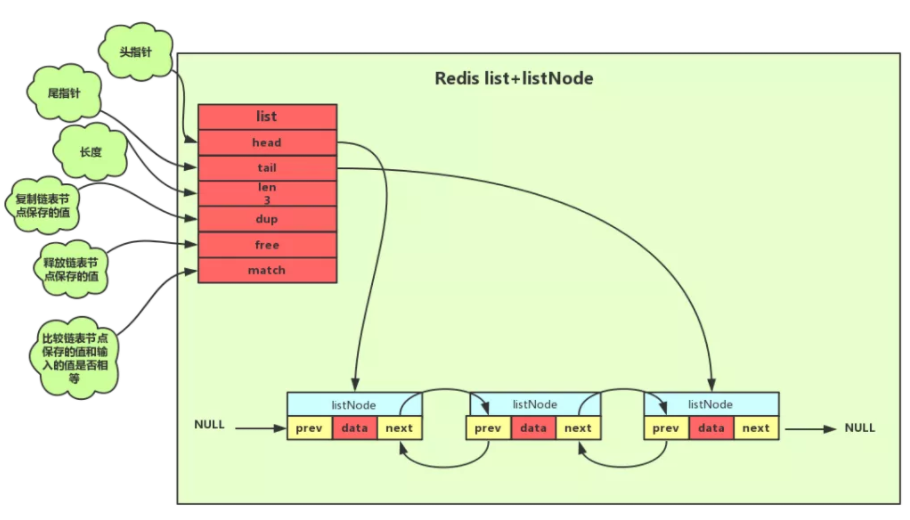
双向链表
Redis 使用的链表是双向链表。为了方便操作,使用了一个 list 结构来持有这个链表。
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void *(*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
}list;
如图所示:
压缩列表
与上面的链表相对应,压缩列表有点儿类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。每个节点上增加一个 length 属性来记录这个节点的长度,这样比较方便地得到下一个节点的位置。
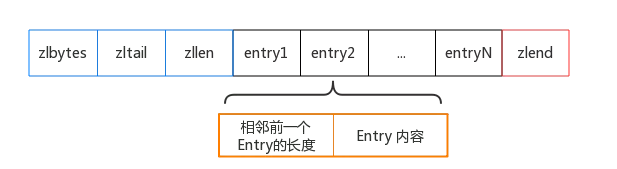
上图的各字段含义为:
- zlbytes:列表的总长度
- zltail:指向最末元素
- zllen:元素的个数
- entry:元素的内容,里面记录了前一个 Entry 的长度,用于方便双向遍历
- zlend:恒为
0xFF,作为 ziplist 的定界符
压缩列表不只是 list 的底层实现,也是 hash 的底层实现之一。当 hash 的元素个数少且内容长度不大时,使用压缩列表来实现。
具体细节参考:内存节省到极致!!!Redis中的压缩表,值得了解...
散列(Hash)类型
hash 底层有两种实现:压缩列表和字典(dict)。压缩列表刚刚上面已经介绍过了,下面主要介绍一下字典的数据结构。
# 储存语法
hset key field value
# 获取
hget key field
# 获取所有列
hgetall key
# 删除
hdel key field
字典(dict)😮
字典与 Java 中的 HashMap 类似,Redis 底层也是使用的散列表作为字典的实现,解决 hash 冲突使用的是链表法。Redis 同样使用了一个数据结构来持有这个散列表:
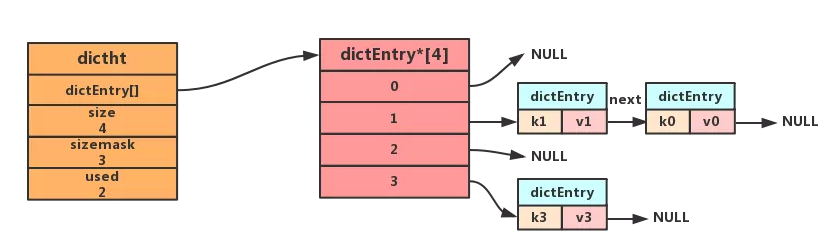
在键增加或减少时,会扩容或缩容,并且进行 rehash,根据 hash 值重新计算索引值。那如果这个字典太大了怎么办呢?
为了解决一次性扩容耗时过多的情况,可以将扩容操作穿插在插入操作的过程中,分批完成。
当负载因子触达阈值之后,只申请新空间,但并不将老的数据搬移到新散列表中。当有新数据要插入时,将新数据插入新散列表中,并且从老的散列表中拿出一个数据放入到新散列表。每次插入一个数据到散列表,都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。这样没有了集中的一次一次性数据搬移,插入操作就都变得很快了。这个过程也被称为 渐进式 rehash。
Set 类型(集合)
set 里面没有重复的集合。set 的实现比较简单。如果是整数类型,就直接使用整数集合 intset。使用二分查找来辅助,速度还是挺快的。不过在插入的时候,由于要移动元素,时间复杂度是 。
如果不是整数类型,就使用上面在 hash 那一节介绍的字典。key 为 set 的值,value 为空。
ZSet 类型(有序集合)
有序集合类型(Sorted Set 或 ZSet)相比于集合类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),与 set 类型不同的是,有序集合中的元素可以排序。
有序集合类型的内部编码有两种:
ziplist(压缩列表):当有序集合的元素个数小于list-max-ziplist-entries配置(默认128个)同时所有值都小于list-max-ziplist-value配置(默认64字节)时使用。ziplist使用更加紧凑的结构实现多个元素的连续存储,更加节省内存。
skiplist(跳跃表):当不满足 ziplist 的要求时,会使用 skiplist。
跳跃表
跳跃表(skiplist)是一种随机化的数据,跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美。查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。

具体的参考数据结构那里的笔记
内部实现
有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
当数据比较少时,有序集合使用的是 ziplist 存储的,有序集合使用 ziplist 格式存储必须满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用 skiplist 结构进行存储。
为什么用跳表而不用红黑树?
- 跳表的实现更加简单,不用旋转节点,相对效率更高
- 跳表在范围查询的时候的效率是高于红黑树的,因为跳表是从山层往下层查找的,上层的区域范围更广,可以快速定位到查询的范围
- 平衡树的插入和删除操作可能引发子树的调整、逻辑复杂,而跳表只需要维护相邻节点即可
- 查找单个key,跳表和平衡树时间复杂度都是O(logN)
HyperLogLog 类型(基数统计)
HyperLogLog(HLL)是一种概率性数据结构,用于进行基数(cardinality)估算,即估计一个集合中不重复元素的数量。它的设计目标是在具有很大基数的集合上占用较小的内存,并且具有高效的插入和查询操作。
HyperLogLog 通过使用固定的内存空间来估计集合的基数,而不会随着集合大小的增加而线性增加内存消耗。它基于哈希函数和位图技术,将元素映射到一个固定大小的位图中。通过统计位图中零位(leading zeros)的数量来估算集合的基数。
HyperLogLog 的估算结果是概率性的,意味着估算值可能会有一定的误差。但是,在大多数实际应用中,HyperLogLog 能够提供非常接近实际基数的估计结果,而且在空间效率和计算效率方面具有很大优势。
在Redis中,HyperLogLog 是作为一种数据结构而被支持的,提供了 PFADD、PFCOUNT 和 PFMERGE 等命令用于插入元素、估算基数和合并多个 HyperLogLog 结构。它广泛应用于许多场景,例如统计网站的独立访客数量、统计广告点击次数、判断用户活跃度等。
内部原理
HyperLogLog (HLL) 的原理基于概率统计和位图技术。它使用哈希函数和位图来实现对集合基数(cardinality)的估计,同时占用固定大小的内存空间。
以下是 HyperLogLog 的主要原理步骤:
初始化位图:创建一个固定大小的位图(通常是 2^b),其中的每个位都被初始化为0。
元素映射:对集合中的每个元素进行哈希处理,得到一个哈希值。这个哈希值包含了一个二进制串,长度为 b,用于标识位图中的位置。
计算前导零位数:对每个元素的哈希值,统计其二进制串中前导零位(leading zeros)的数量。
更新位图:将位图中对应位置的位值更新为当前元素的前导零位数中的最大值。
估算基数:通过统计位图中零位(leading zeros)的平均数量,根据基数估算算法(例如,使用调和平均值)来估算集合的基数。
HyperLogLog 通过统计位图中零位的数量来估算基数,因为当集合中有很多元素时,前导零位很可能是均匀分布的,而在位图中出现连续的零位可能性较小。通过统计零位的平均数量,可以推导出基数的近似值。
下面画个图来表示一下
+-----------------------------------------+
| Register 1 |
+-----------------------------------------+
| Register 2 |
+-----------------------------------------+
| Register 3 |
+-----------------------------------------+
| ... |
+-----------------------------------------+
| Register n |
+-----------------------------------------+
| Bit Mapping |
+-----------------------------------------+
在这个示意图中,每个水平的矩形框代表一个寄存器(register),寄存器用于存储某个元素的哈希值。通常,HyperLogLog 使用一定数量的寄存器来记录不同哈希值的出现情况。
下方的区域表示位图(bit mapping),其中每个位(bit)代表一个寄存器是否已经被某个元素的哈希值所占用。位图中的每个位通常使用 1 或 0 来表示寄存器是否已被占用。
通过将元素的哈希值映射到对应的寄存器,并记录位图中相应位的状态,HyperLogLog 可以估算基数(不同元素的数量)。基于哈希函数和位图的统计算法,HyperLogLog 可以在占用较小内存的情况下进行基数估算。
需要注意的是,HyperLogLog 的估算结果是概率性的,估算值可能存在一定的误差。误差的范围通常受位图大小的影响,位图越大,误差越小。通常情况下,HyperLogLog 能够提供非常接近实际基数的估计结果,同时具有较小的内存占用和高效的计算性能。